Дубли страниц – страницы с одинаковым контентом, доступным из разных URL. Рассмотрим самые важные вопросы: как найти дубли страниц, чем вредны дубликаты страниц, частые причины дублирования, удаление дубликатов, примеры.
Чем вредны дубли страниц
План статьи
Проблема дублей на сайте вызывает у поисковых систем ряд вопросов – какая страница каноническая, какую страницу показывать в поисковой выдаче и является ли сайт, показывающий посетителям дубликаты страниц качественной площадкой.
Google сражается с дубликатами страниц с помощью фильтра Panda, начиная с 2011 года. В настоящее время фильтр является неотъемлемой частью формулы ранжирования. При наличии Панды сайт теряет большую часть трафика из поисковой системы.
Частые причины дублирования страниц
Наиболее частой причиной дублирования страниц является особенность строения CMS, на которых разработан сайт. Например, в Joomla есть множество конструкций URL, которыми будет доступен тот же контент. Даже в последних версиях WordPress есть вариант доступности контента записей по конструкции site.ru/postID и site.ru/ЧПУ. А в магазинной CMS Opencart: при ЧПУ с включением названия категории – расположение товара к разным категориям. Некоторые неопытные SEO-оптимизаторы берут в основу один контент и размножают его, изменяя лишь несколько слов в тексте. По такому же принципу работают и дорвии. Такое дублирование называется частичным и за такое дублирование могут быть наложены санкции (Google Panda и др.).
Вторая популярная версия дублирования – доступность страниц с www и без (www.site.ru и site.ru). При таком дублировании все версии сайта должны быть добавлены в Google Webmaster Tools, после чего уже избавляться от них.
Третья по популярности вариация дубликатов – наличие контента со слешем в конце URL и без него.
Поиск и удаление дублей страниц на сайте входит в сервис Внутренняя SEO оптимизация сайта. Экономьте, заказывая у индивидуального специалиста.
Сервисы и приложения поиска
Наиболее быстрый и обычно точный способ – найти дубликаты страниц по Title и мета-тегам. Ниже – сервисы и программы, которыми пользуюсь сам.
Сервисы для поиска дублей по Title и мета-тегам:
- Инструмент "Аудит сайта" в сервисе Serpstat (комплексные сервисы для SEO, PPC ~$100/месяц).
- JetOctopus.
- Ahrefs.
- Остальные, если знаете, пишите в комментариях.
Программы для поиска дублей по Title и мета-тегам:
- Website Auditor от SEO Power Suite (Mac, Windows, Linux, ~$50/однократно).
- Netpeak Spider (Windows только, $14/месяц).
- Xenu (Windows only, free).
- Screaming Frog.
Программы для поиска дублей по контенту:
Если знаете подобный софт – напишите в комментарии контактам – добавлю в список.
Основные способы избавления от дублей страниц на сайте
- Использовать rel="canonical", указывающий на каноническую версию страницы. Лучший способ избавиться от дублей. При использовании caonical практика показала, что весы дублирующих страниц склеиваются, что хорошо для продвижения.
- Закрыть дублируемые страницы от индексации. Можно закрывать конструкциями в robots.txt (как пользоваться robots.txt) или наличием на странице мета-тега .
- Добавить 301 редирект с дублирующей страницы на основную. Подходит при дублировании www/без, слэш на конце/без. Настраивается в файле .htaccess или специальными плагинами.
Как найти дубли страниц: Примеры
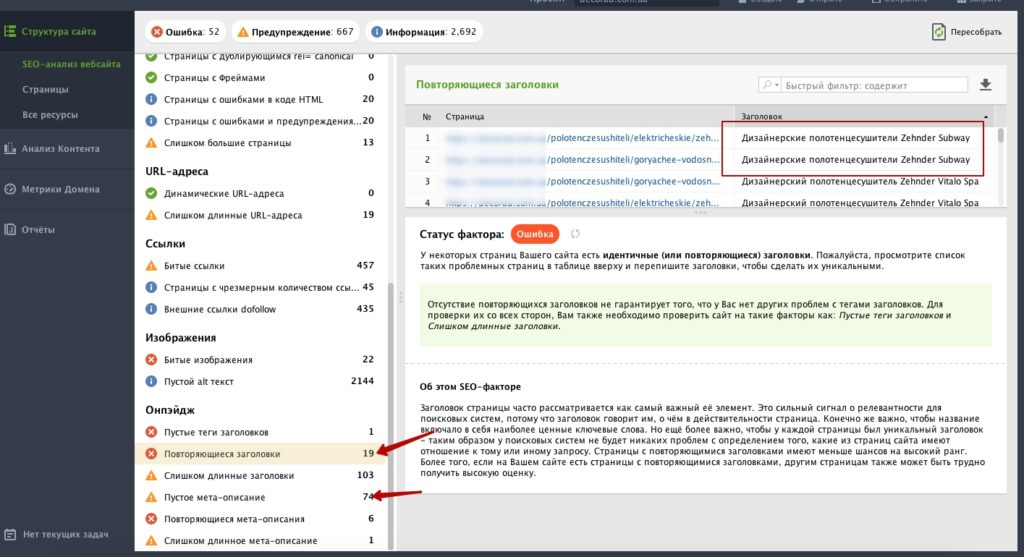
Поиск дублей с помощью Serpstat
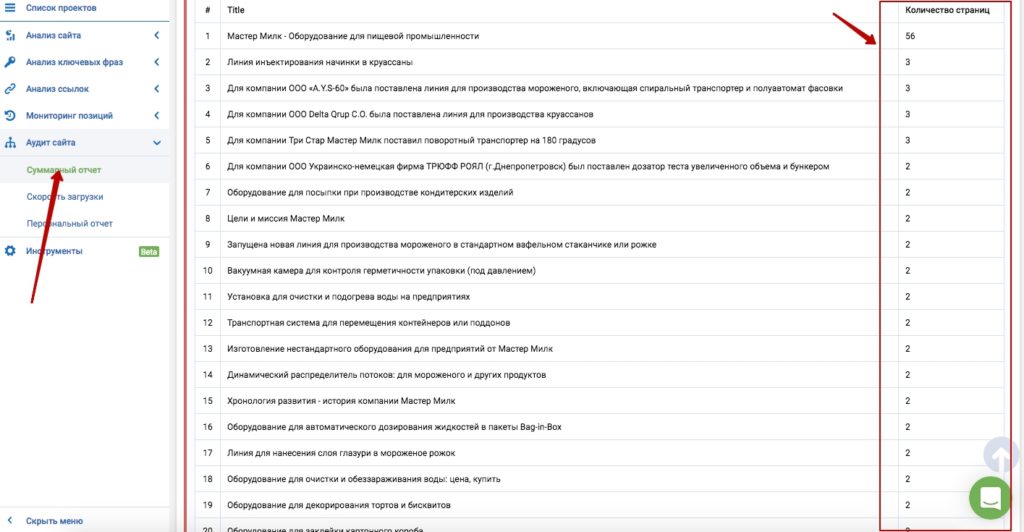
Поиск дублей с помощью Website Auditor